Relatórios Avançados
O
IW permite que sejam publicados relatórios avançados
desenvolvidos com tecnologia JRXML (Jasper Report). Esses relatórios
podem ser desenvolvidos a partir do ambiente gráfico “iReport”
e publicados naturalmente na relação de relatórios
acessíveis pelos usuários através do menu ou
painéis de navegação.
Nota:
Acesse o link :
http://sourceforge.net/projects/ireport/files/iReport/ para fazer
download gratuito do ambiente de desenvolvimento iReport Design. O
iReport Design é um software que possui versão free
(que pode ser baixada na url citada acima) desenvolvido pela Jasper
Soft. O Jasper Report é um dos ambientes de desenvolvimento de
relatórios mais utilizados no mundo todo. O iReport Design é
basicamente uma ferramenta gráfica que torna o trabalho de
edição dos fontes do relatório (arquivos xml)
mais amigável e simples. Existe ampla bibliografia disponível
sobre esse ambiente na internet. O IW está correntemente
preparado para receber relatórios gerados até a versão
4.02 do iReport.
Esse
manual descreve o processo de desenvolvimento de relatórios
usando o iReport Design com o objetivo de gerar relatórios que
sejam publicáveis no IW.
Através da criação
de relatórios avançados é possível
combinar diversos relatórios (uso de sub-reports) em uma mesma
impressão bem como é possível combinar diversos
modelos de gráficos, com dados tabulares em um único
relatório oferecendo grande eficiência e elegância
na apresentação das informações
gerenciais.
As figuras a seguir mostram exemplos de relatórios avançados :
Tanto
relatórios de gride quanto relatórios baseados em
comandos SQL poderão ser implementados através do uso
da arquitetura de processamento de relatórios avançados.
Método
de Desenvolvimento de Relatórios Avançados Publicáveis
no IW
(a)
Desenvolvendo Relatórios Avançados Baseados em Comandos
SQL
(b) Convertendo relatórios tradicionais para
Relatórios Avançados
(a)
Desenvolvendo Relatórios Avançados Baseados em Comandos
SQL
[01]
– Passo
1 :
Elaborando o comando SQL do
relatório
[02] – Passo
2 :
Gerando um “DataSource”
e um arquivo .jrxml de semente para elaboração do
relatório avançado
[03] – Passo
3 :
Preparação para
o Desenvolvimento do Relatório no iReport Designer
[04]
– Passo
4 :
Desenvolvimento
do Relatório no iReport
[05] – Passo
5 :
Publicação
do Relatório Avançado no IW
Passo
1: Elaborando o comando SQL do
relatório
Elabore o comando SQL que fará
a obtenção dos dados que serão trabalhados no
relatório. Usuários com status de “desenvolvedores”
no IW podem utilizar a interface “F00129 - Sql & Debug”
(menu: Ferramentas – Sql & Debug) para desenvolver/testar o
comando SQL para o relatório.
Notas
importantes:
(a) Basicamente vamos elaborar dois comandos
a saber: (a.1) Comando no qual os parâmetros de entrada para o
comando (ex.: datas de início e término de um período
de tempo que será utilizado como filtro no relatório)
estão substituídos por seus valores de exemplo e (a.2)
Comando no qual os parâmetros de entrada estão escritos
na sintaxe de parâmetros do IW.
Exemplo: Vamos supor um
comando que fará um cálculo de contagem de consultas
realizadas por especialidade e por paciente em um determinado período
de tempo:
Comando
(a.1)
Sintaxe para oracle:
Select
count(*) as qtde_consultas , b.codename as nome_especialidade ,
e.name as nome_paciente , e.gender as sexo_paciente , b.id as
nro_atendimento
from capevolution a , scccode b , capadmission c ,
glbpatient d , glbperson e
where
a.scspeciality = b.id
and
a.idadmission = c.id
and c.idpatient = d.id
and d.idperson =
e.id
and a.startdate >= to_date('01/01/2006',
'dd/mm/yyyy') and
a.startdate < (to_date('31/01/2006',
'dd/mm/yyyy') + 1 )
group
by b.codename , e.name , e.gender, b.id
order by b.codename asc ,
e.name asc
Sintaxe para SqlServer:
Select
count(*) as qtde_consultas , b.codename as nome_especialidade ,
e.name as nome_paciente , e.gender as sexo_paciente , b.id as
nro_atendimento
from capevolution a , scccode b , capadmission c
, glbpatient d , glbperson e
where
a.scspeciality = b.id
and
a.idadmission = c.id
and c.idpatient = d.id
and d.idperson =
e.id
and a.startdate >= Cast('01/01/2006'
as DateTime) and
a.startdate < (Cast('31/01/2006'
as DateTime) + 1 )
group
by b.codename , e.name , e.gender, b.id
order by b.codename asc ,
e.name asc
Nesse
comando foi utilizado como período de exemplo o mês de
janeiro de 2006 inteiro : Ou seja, de '01/01/2006' até
'31/01/2006' inclusive.
Esse
comando (a.1) é que
será utilizado para obtenção da massa de dados
(Data Source) para o desenvolvimento do relatório.
Comando
(a.2)
Sintaxe para oracle:
Select
count(*) as qtde_consultas ,
b.codename as nome_especialidade , e.name as nome_paciente , e.gender
as sexo_paciente , b.id as nro_atendimento
from capevolution a , scccode b , capadmission c , glbpatient d , glbperson e
where
a.scspeciality = b.id
and a.idadmission = c.id
and c.idpatient = d.id
and d.idperson = e.id
and a.startdate >= to_date('$P{Periodo_de}', 'dd/mm/yyyy') and a.startdate < (to_date('$P{Periodo_ate', 'dd/mm/yyyy') + 1 )
group by b.codename , e.name , e.gender, b.id
order by b.codename asc , e.name asc
Sintaxe
para SqlServer:
Select
count(*)
as qtde_consultas , b.codename as nome_especialidade , e.name as
nome_paciente , e.gender as sexo_paciente , b.id as nro_atendimento
from capevolution a , scccode b , capadmission c , glbpatient d , glbperson e
where
a.scspeciality = b.id
and a.idadmission = c.id
and c.idpatient = d.id
and d.idperson = e.id
and a.startdate >= Cast('$P{Periodo_de}' as DateTime) and a.startdate < (Cast('$P{Periodo_ate}' as DateTime) + 1 )
group by b.codename , e.name , e.gender, b.id
order by b.codename asc , e.name asc
Note
que nos comandos (a.2) ao invés de colocarmos valores de datas
fixos , o comando foi escrito com a sintaxe de substituição
de parâmetros do IW. O comando (a.2) será utilizado
na etapa final do desenvolvimento do relatório avançado.
Basicamente vamos editar diretamente o xml final inserindo na sintaxe
do data source o comando (a.2). Isso será visto em detalhes
mais adiante nesse manual.
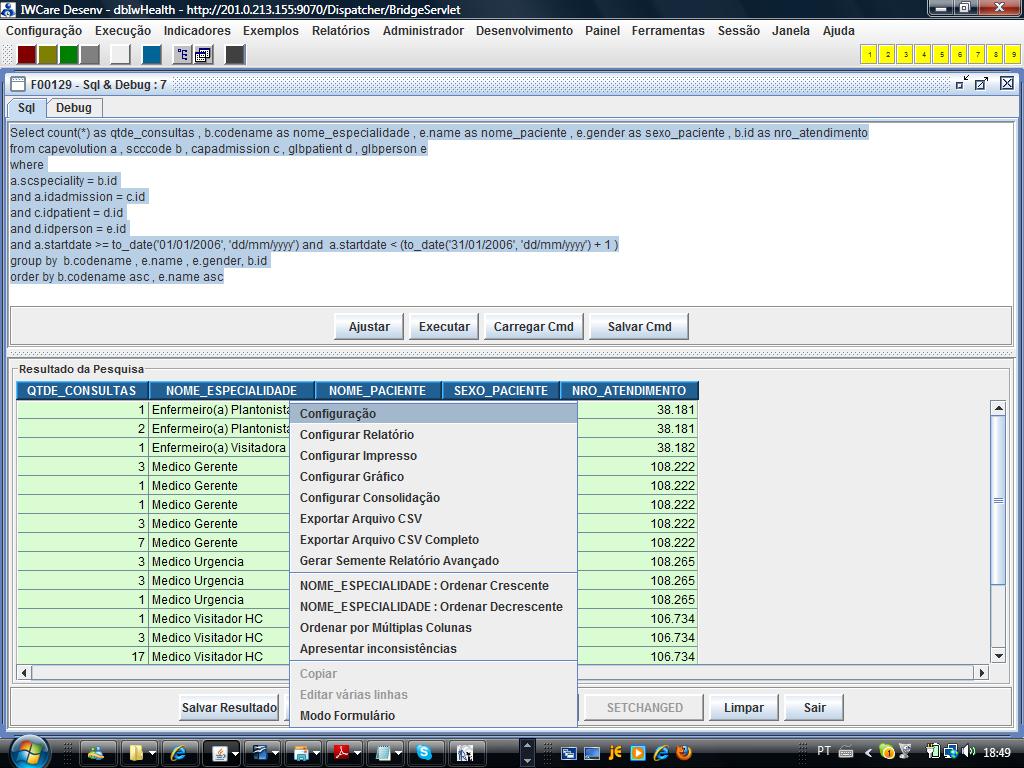
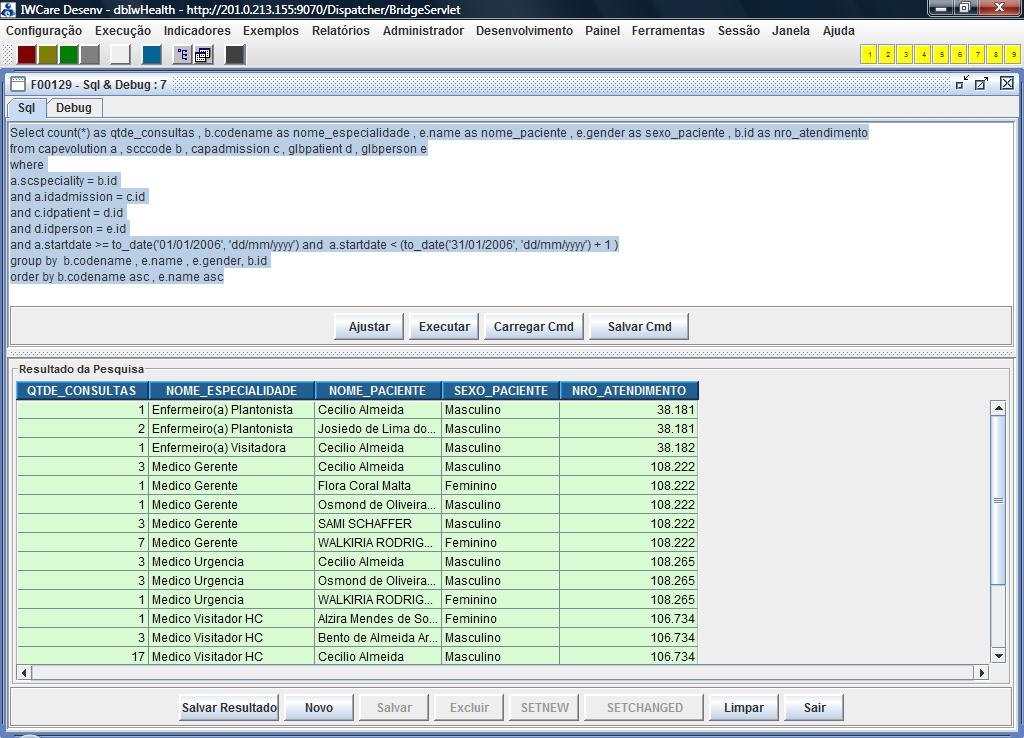
A figura a seguir ilustra a execução desse comando através da interface “F00129 - Sql & Debug”:

Realizando
a Tradução de Campos associados a Constantes no
IW
Notem que a coluna denominada
“SEXO_PACIENTE” acima retornou valores inteiros (1,2) que
são os valores do padrão de codificação
das opções de valores para o atributo “sexo
(gênero)” dos pacientes. Dentro da interface desktop
(java) do IW a exibição desse tipo de coluna nos grides
da aplicação é configurada normalmente
relacionada a uma constante (K_GLB_GENDER) onde ficam gravadas as
“traduções” dos valores (ex.: 1=Masculino ,
2 = Feminino) e o IW no momento da exibição do gride
faz a “tradução automaticamente”. No caso
da exportação de um arquivo .csv de Data Source devemos
utilizar exatamente o mesmo recurso para termos a informação
traduzida no gride (ex.: Masculino , Feminino ao invés de 1 ,
2). Para isso basta “associar a constante à coluna
diretamente no gride na própria interface F00129”.
Para isso siga os seguintes passos:
I) Clique com botão
direito do mouse sobre o cabeçalho do gride e selecione a
opção “Configuração”. A
figura a seguir ilustra essa edição:
O
IW irá abrir a caixa de diálogo de configuração
do gride que ilustramos a seguir: Localize a coluna desejada
(SEXO_PACIENTE) e clique “Config → Local” conforme
ilustrado a seguir:
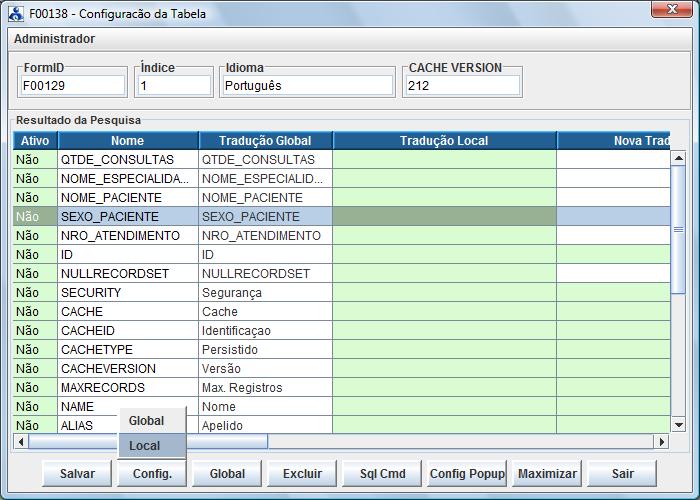
O IW irá abrir a caixa de diálogo de parametrização das características do campo selecionado que ilustramos a seguir:
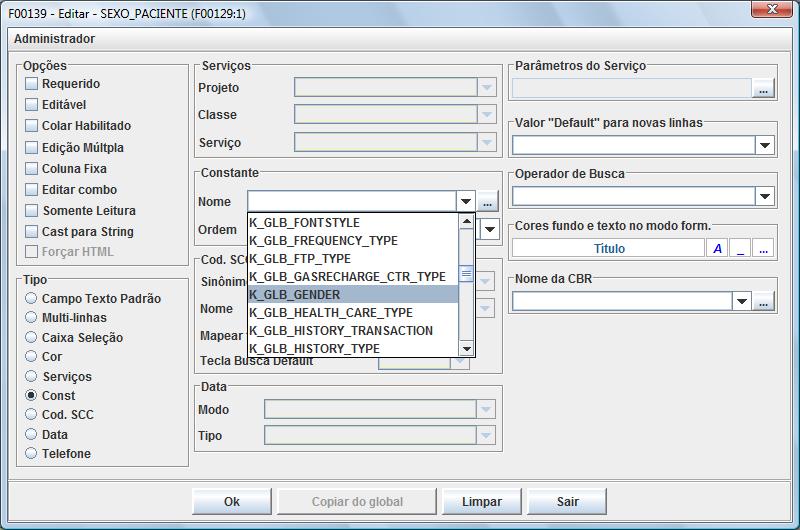
Selecione
: Tipo = Const e selecione a constante K_GLB_GENDER conforme
ilustrado acima. Em seguida clique no botão “ok” e
em seguida clique no botão “Salvar” (na interface
F00138). Note que o IW irá re-exibir o gride com o resultado
do comando SQL já com as devidas traduções
(sexo: masculino ou femino). A figura a seguir ilustra o resultado
dessa edição :
IMPORTANTE
: Nessas colunas que são associadas a “constantes”
no IW, tipicamente será mais prático deixar o comando
retornar o nome nativo da coluna no IW. Por exemplo: Se ao invés
de renomearmos a coluna e.gender as sexo_paciente como
foi feito no nosso exemplo , deixássemos retornar no comando
simplesmente e.gender o
IW já irá trazer a coluna traduzidas automaticamente
com base na tradução “global” gravada no
dicionário do IW. A figura a seguir ilustra o resultado da
execução do comando modificado:
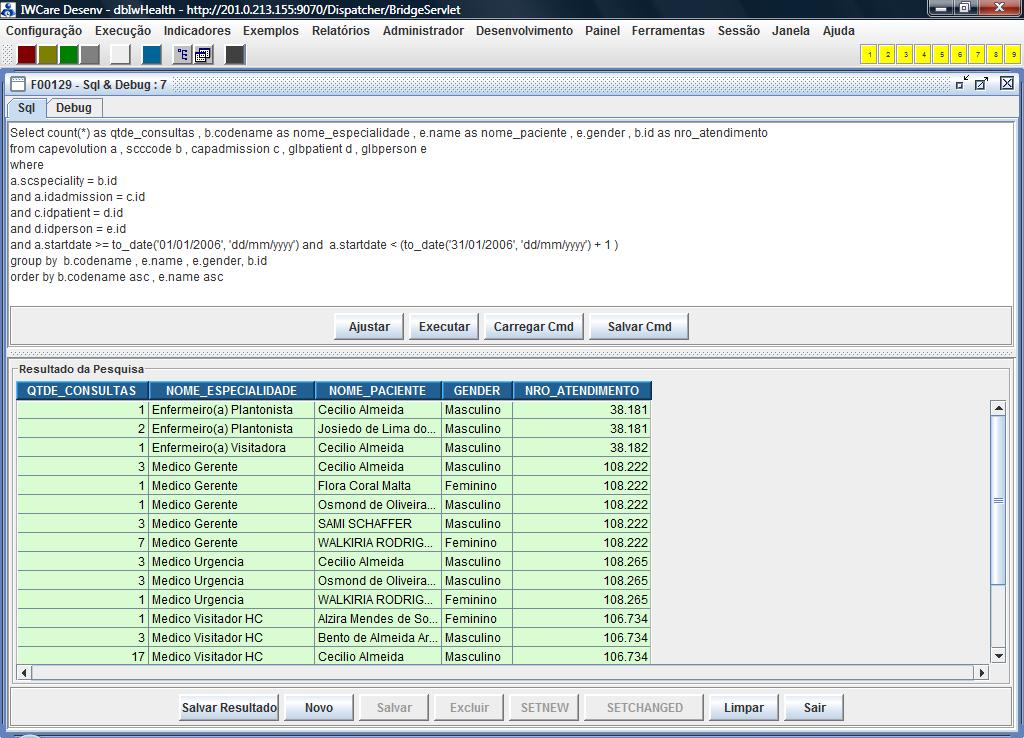
Notem
que a valoração da coluna “gender” já
vem traduzida.
Nota
Técnica: Ao
exportamos futuramente o data source (arquivo .csv) e a “semente
.jrxml” para o desenvolvimento do relatório avançado
, aqueles campos do gride que tenham sido associados a “constantes”
já serão associados a essas mesmas “constantes”
no xml do relatório avançado. Em tempo de execução
desses relatórios, o IW fará a tradução
dos valores dos KEYINDEX (ex.:1,2, etc) pelas suas devidas traduções
(ex.: feminino, masculino) automaticamente . Esse comportamento da
infra-estrutura do IW visa simplificar a construção dos
comandos SQL para relatórios avançados desobrigando os
desenvolvedores de envolver tabelas de tradução de
constantes nos comandos Sql.
Passo
2 :
Gerando um “DataSource” e arquivo .jrxml semente para
elaboração do relatório
(2.1)
Gerando o arquivo “Data Source” para elaboração
do relatório avançado
Para
gerar o DataSource a ser utilizado dentro do iReport vamos utilizar o
recurso de gerar um arquivo “.csv” contendo a massa de
dados de base para o desenvolvimento do relatório
(datasource). Para obter esse arquivo “.csv” vamos
basicamente acessar a interface “Sql&Debug” do
Incoway e vamos executar o comando SQL do relatório. A figura
a seguir ilustra essa interface F00129 (menu: Ferramentas – Sql
& Debug) :
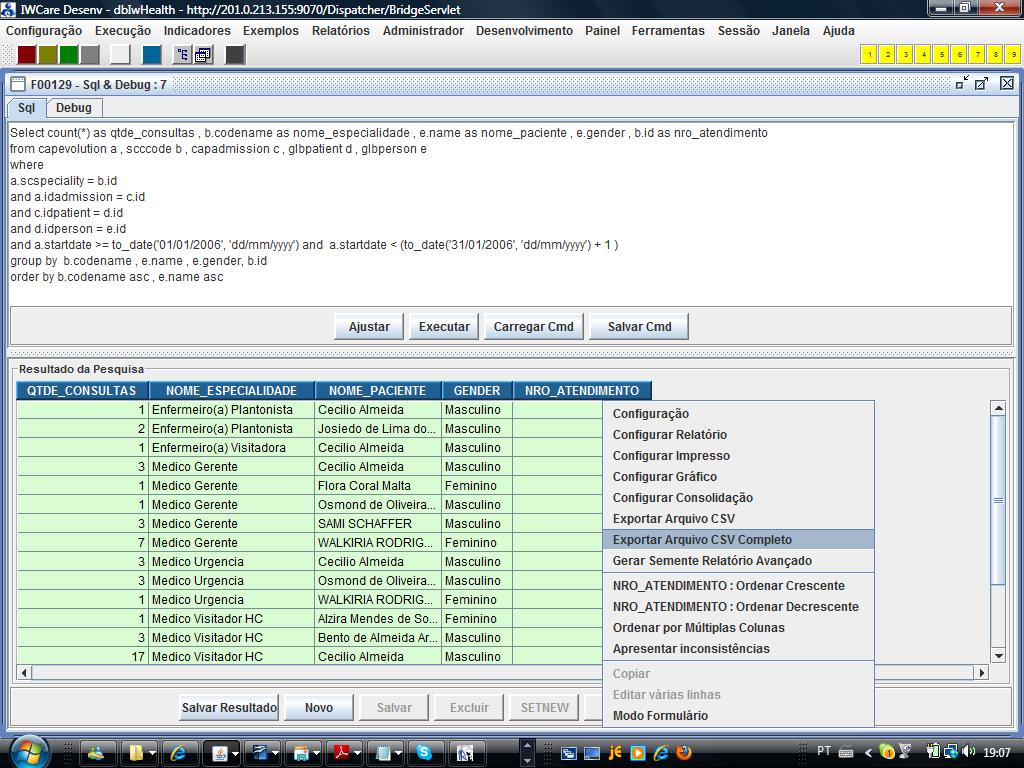
Após
executar o comando sql na interface F00129 clique com o botão
direito do mouse sobre o cabeçalho do gride que apresenta o
resultado do comando sql e selecione a opção “Exportar
Arquivo CSV Completo” conforme ilustrado acima. O IW irá
abrir a caixa de diálogo tradicional para a salva de um
arquivo conforme ilustrado abaixo:
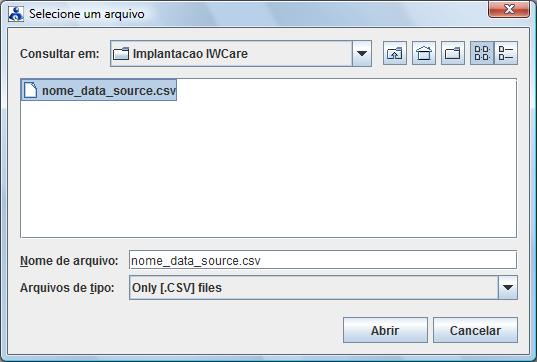
Selecione
um diretório destino para a salva do arquivo e informe um nome
para esse arquivo : Atenção : utilize extensão
.csv para o arquivo e clique no botão “Abrir”. O
IW irá gerar um arquivo .csv contendo as informações
que estavam no gride. Esse arquivo será utilizado no “iReport”
para definir um “DataSource” que será utilizado no
desenvolvimento e testes do relatório avançado.
IMPORTANTE:
Ao exportar os dados do gride para o arquivo .csv o IW irá
acrescentar colunas no data source, sempre que houver colunas no
gride associadas a “constantes do sistema de traduções
do IW”. No nosso exemplo associamos a coluna denominada
SEXO_PACIENTE à constante K_GLB_GENDER, isso fez com que fosse
exibido no gride as traduções do atributo sexo (ex.:
“masculino” ou “feminino” ao invés dos
valores do KEYINDEX da constante (1 ou 2)). Nesse caso o IW irá
acrescentar no data source (arquivo .csv) uma coluna denominada
SEXO_PACIENTE_#KEYINDEX. Essa coluna será valorada com
os valores do KEYINDEX da constante (ou seja, valores originais
obtidos da coluna sem passar pela tradução da
constante). Nesse exemplo a coluna SEXO_PACIENTE_#KEYINDEX receberá
o valor 1 quando se tratar de um paciente do sexo “masculino”
e 2 quando se tratar de um paciente do sexo “feminino”. O
objetivo desse comportamento do IW é permitir que sejam
realizados processamentos de (lógicas) no código fonte
do relatório baseadas nos valores dessas colunas associadas à
constantes no IW de forma mais “robusta”, ou seja, ao
invés de utilizarmos expressões baseadas na coluna
SEXO_PACIENTE onde teríamos que utilizar os termos traduzidos
nas expressões (“masculino, “feminino”),
como uma boa prática de programação, deveremos
utilizar em expressões a coluna SEXO_PACIENTE_#KEYINDEX sobre
os valores não traduzidos (1 ou 2). Se adotarmos essa prática
de programação teremos relatórios mais
“robustos” que continuarão funcionando normalmente
caso as traduções das constantes venham a ser alteradas
na base de dados do cliente.
(2.2)
Gerando o arquivo .jrxml de semente para elaboração do
relatório
O
arquivo de “semente” para elaboração de
relatórios avançados consiste em um arquivo com
extensão .jrxml que contem todas as definições
dos campos do “Data Source” que será utilizado no
processamento do relatório. Para gerar o arquivo de semente
basta utilizar a opção “Gerar Semente Relatorio
Avançado” que fica logo abaixo da opção
“Exportar arquivo CSV Completo” (conforme ilustração
já exibida acima). Ao acionar essa opção o IW
irá lançar a mesma caixa de diálogo solicitando
um nome para o arquivo .jrxml e o local (diretório) para salva
do mesmo.
Após a construção do comando
sql , exportação do Data Source (arquivo .csv) e da
semente (arquivo .jrxml) estamos prontos para iniciar o
desenvolvimento do relatório avançado propriamente dito
usando agora o iReport Designer.
Passo 3 : Preparação para o Desenvolvimento do Relatório no iReport Designer
Para
iniciamos as atividades de desenvolvimento do relatório
propriamente dito deveremos executar os seguintes passos:
3.1
– Lançar o
aplicativo iReport propriamente dito na sua estação de
trabalho
3.2 – Carregar o
modelo “semente” do relatório avançado
3.3
– Carregar o arquivo Datasource
(arquivo .csv)
3.1
- Lançar o aplicativo iReport propriamente dito na sua estação
de trabalho
Lance
o iReport na sua estação de trabalho. A figura a seguir
ilustra a tela de abertura do iReport Designer :
3.2
– Carregar o modelo “semente” do relatório
avançado no ambiente de desenvolvimento do iReport
Em
seguida acesse “menu-arquivo : Open” e carregue o arquivo
.jrxml “semente” gerado no passo 2.2 descrito
anteriormente.
A figura a seguir ilustra a interface do
iReport após esse passo: Essa é uma interface que
permite a edição dos arquivos .jrxml de maneira gráfica
de forma mais confortável e segura.
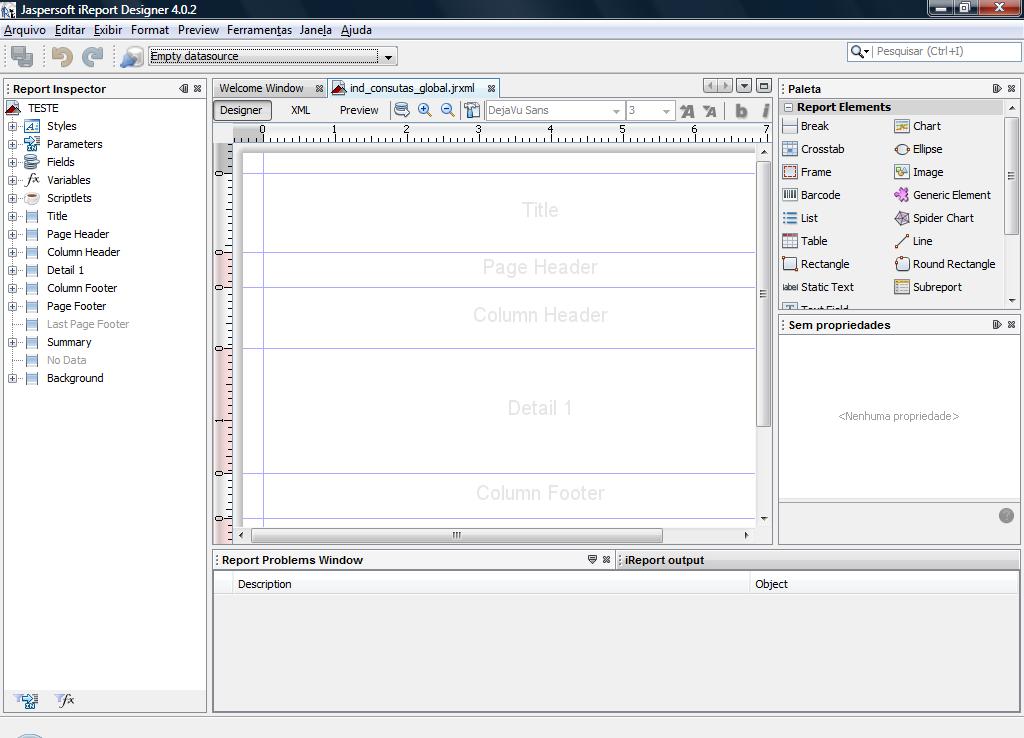
Lembre-se
que dissemos que o arquivo .jrxml “semente” gerado pelo
IW já possui a declaração dos campos “fields”
(obtidos do resultado do comando sql). Visualize esses “fieds”
clicando na opção “Fields” no lado esquerdo
da interface . A figura a seguir ilustra essa navegação:
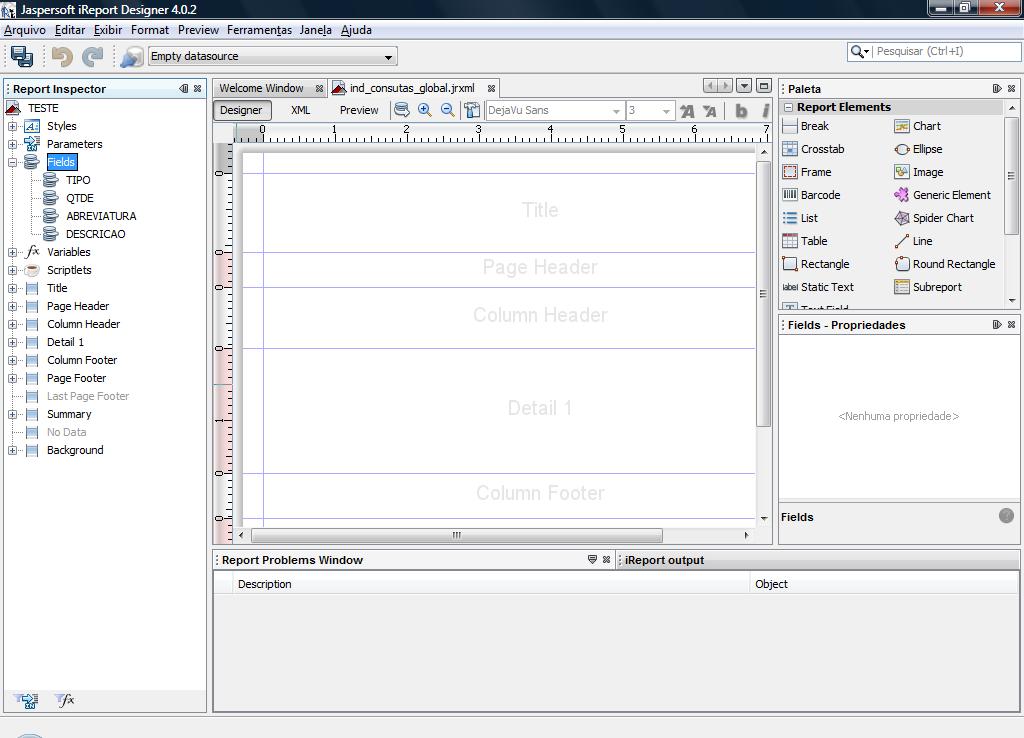
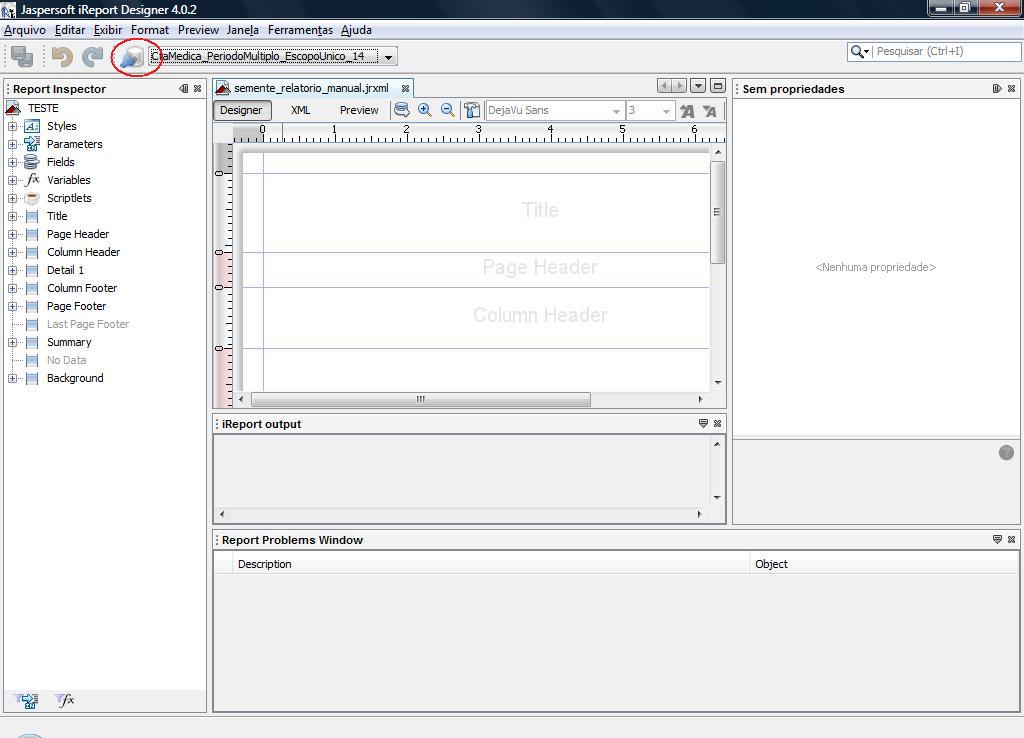
3.3 – Carregar o arquivo Datasource (arquivo .csv)
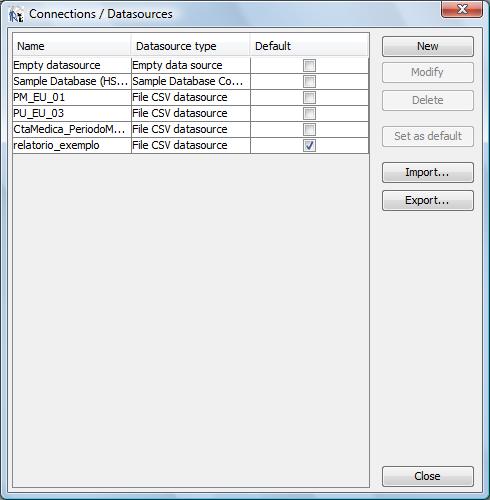
Para proceder a carga do “Data Source” no iReport clique no botão destacado pelo círculo vermelho na ilustração abaixo:
Quando
clicamos nesse botão o iReport irá abrir a seguinte
caixa de diálogo:
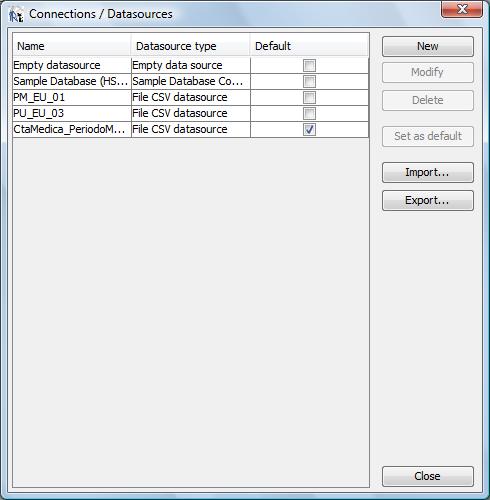
Clique
no botão denominado “New” para proceder a carga do
arquivo .csv. O iReport irá abrir a seguinte caixa de diálogo
para seleção do “tipo de data source”:
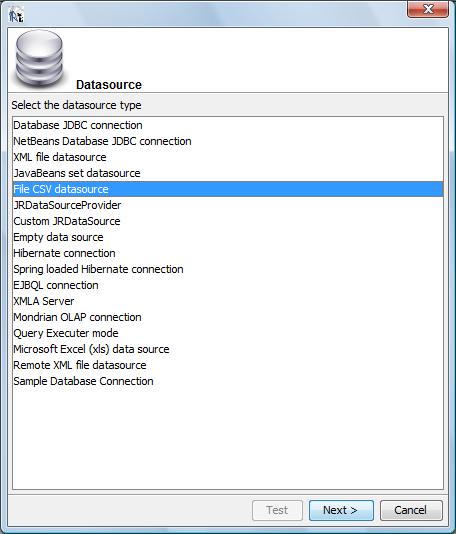
Selecione,
conforme ilustrado acima a opção “File Csv Data
Source”. O iReport irá abrir então a caixa de
diálogo ilustrada abaixo:
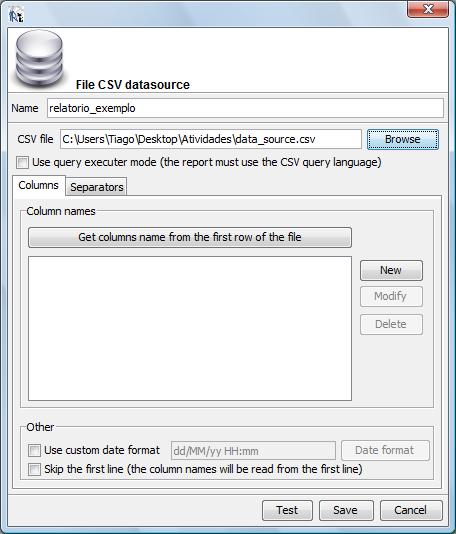
No
campo “name” informe um nome para o Data Source e clique
no botão “Browse” para navegar na estrutura de
diretórios da sua estação de trabalho e
selecionar o arquivo .csv contendo o data source para desenvolvimento
do nosso relatório exemplo (vide tópico 2.1).
Em seguida clique na sub-aba denominada “Separators” que ilustramos abaixo:
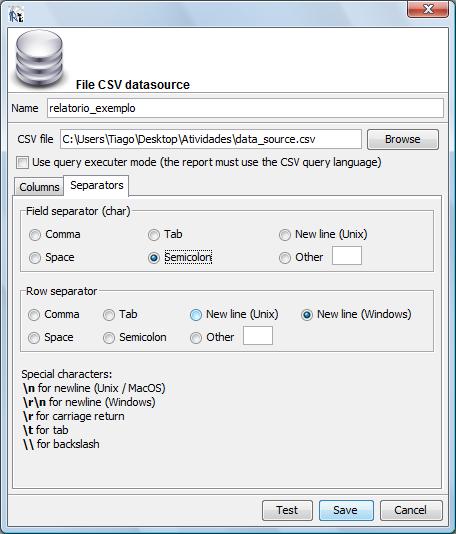
Selecione
a opção “semi-colon” (ponto e vírgula)
como separador de colunas e “New line (windows)” como
separador de linhas. Em seguida retorne para a sub-aba denominada
“Columns” e clique no botão denominado “Get
columns names from the first row of the file”. Após esse
comando o iReport irá apresentar as os nomes das colunas que
ele extraiu do arquivo .csv (Data Source). A figura abaixo ilustra
essa situação:
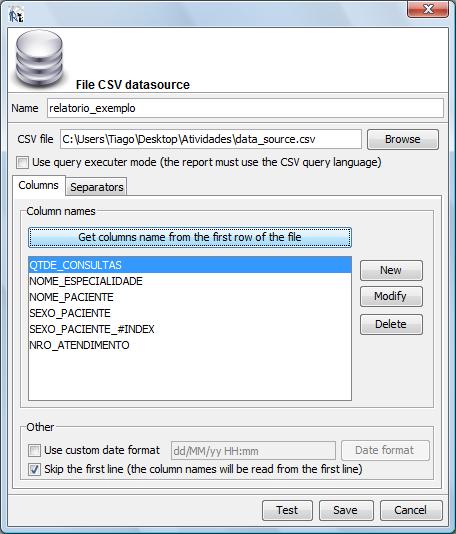
IMPORTANTE:
O formato de datas a ser setado no data source deverá ser
“yyMMddHHmmssZ”.
Para setar esse formato de datas clique inicialmente ative a caixa de
checagem denominada “use custom date format” e em seguida
clique no botão denominado “Date format”.
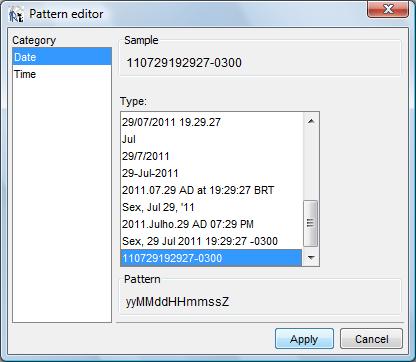
Selecione
a opção ilustrada acima yyMMddHHmmssZ
e
clique no botão “Apply”. A caixa de diálogo
de configuração do Data Source ficará na
condição que ilustramos abaixo:
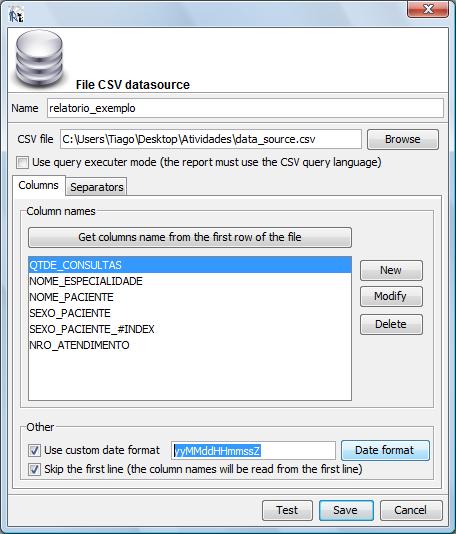
Para
finalizar a configuração do Data Source clique no botão
denominado “Test” ilustrado acima. O iReport irá
realizar um teste sobre o novo Data Source que acabamos de criar e
deverá emitir uma caixa de diálogo com a informação
“Connection test successful” conforme ilustramos a
seguir:
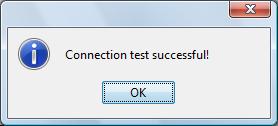
IMPORTANTE:
Após realizar o testes de conexão salve o novo “Data
Source” (clique no botão “Save” ilustrado na
caixa de diálogo de criação do Data Source).Ao
encerrar a caixa de diálogo de definição do novo
“Data Source” o iReport irá retornar para a caixa
de diálogo agora exibindo na listagem o novo Data Source que
acabamos de configurar na condição “default”
= ticado (indicando que esse é o data source que será
executado por default no desenvolvimento do relatório. A
figura a seguir ilustra o que acabamos de dizer: